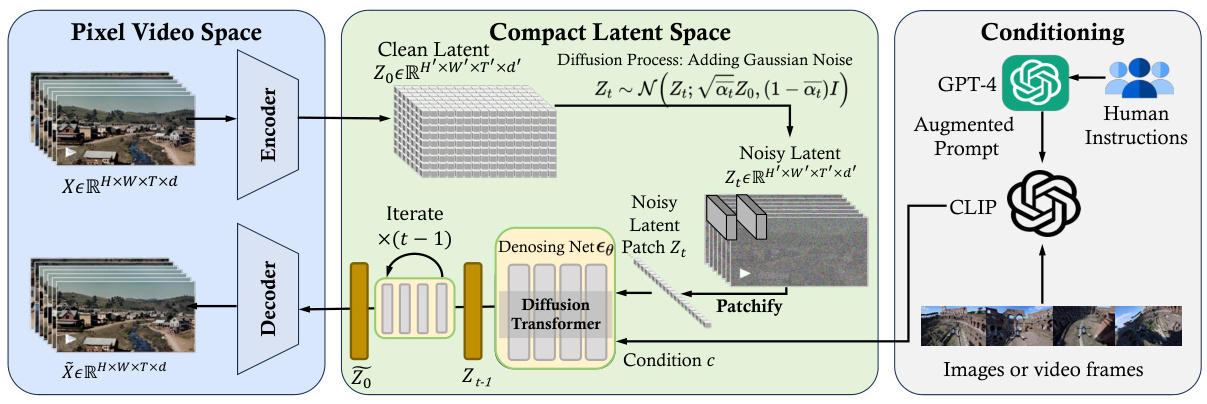
OpenAI的Sora项目采用了Diffusion Transformers(DiT)模型作为其核心架构,结合了扩散模型和Transformer技术,以实现高质量的视频生成。以下是关于DiT模型和编码器-解码器结构的详细介绍:
Diffusion Transformers (DiT) 模型
DiT模型是Sora项目的核心组件之一,它结合了扩散模型(Diffusion Models)和Transformer架构的优势。具体来说,DiT模型包括以下几个主要部分:
1. 变分自编码器(VAE) :用于视频数据的压缩和解压缩,将视频数据映射到低维隐空间,以减少冗余信息并提高数据处理效率。
2. 视觉变换器(ViT) :替代传统的U-Net结构,用于处理图像的潜在表示。ViT通过将图像分割成小块并嵌入到向量空间中,捕捉图像的全局结构。
3. 去噪扩散概率模型(DDPM) :通过逐步添加噪声并学习去除噪声的过程来生成新数据。这一过程使得DiT能够从噪声数据中恢复出清晰、高质量的图像或视频内容。
4. VAE解码器:将生成的隐变量映射回像素空间,完成视频生成任务。
编码器-解码器结构
Sora模型采用了编码器-解码器架构,通过这一架构处理含噪点的输入图像,并在每一步预测出更清晰的图像版本。具体来说:
1. 编码器:包括变分自编码器(VAE)和视觉变换器(ViT),用于将视频数据压缩到低维潜在空间,并进行特征提取。
2. 解码器:通过视觉解码器将生成的隐变量映射回像素空间,从而生成高质量的视频内容。
3. 条件化处理:利用文本编码器将文本指令转换为与图像或视频帧相关的嵌入表示,然后结合这些条件信息生成新的视频帧序列。
DiT网络结构
DiT网络结构包括多个模块,其中DITBlock是核心子模块,集成了自适应归一化层、注意力机制和多头MLP等组件,用于处理输入特征并生成输出。DIT的forward过程涉及嵌入、时间步嵌入、通道拼接和最终层输出,同时支持无分类器引导的条件控制权重参数。
性能与应用
DiT模型在类条件ImageNet基准测试中表现出色,特别是在256×256分辨率下实现了2.27的FID值,证明了其生成高质量图像的能力。此外,DiT模型具有良好的可扩展性,通过增加模型复杂度可以显著提升生成图像质量。
Sora模型利用DiT技术展示了在视频生成领域的巨大潜力,尤其是在处理大规模数据集和生成高质量图像方面。通过增加模型规模和计算资源投入,可以进一步提升图像质量。
综上所述,OpenAI的Sora项目通过结合扩散模型和Transformer技术,实现了高效且有效的视频生成能力,展示了DiT模型在视频生成领域的强大潜力和应用前景。
上一篇:OpenAI Sora项目在游戏领域的实时路径规划与运动预测技术是如何实现的?
下一篇:服务器漏洞扫描工具有哪些推荐?
Copyright © 2013-2020 idc10000.net. All Rights Reserved. 一万网络 朗玥科技有限公司 版权所有 深圳市朗玥科技有限公司 粤ICP备07026347号
本网站的域名注册业务代理北京新网数码信息技术有限公司的产品

